引言
记一次IoT项目中由于线程使用不当,无限增加导致OOM的事故,记录整个分析和调优过程。
问题现象
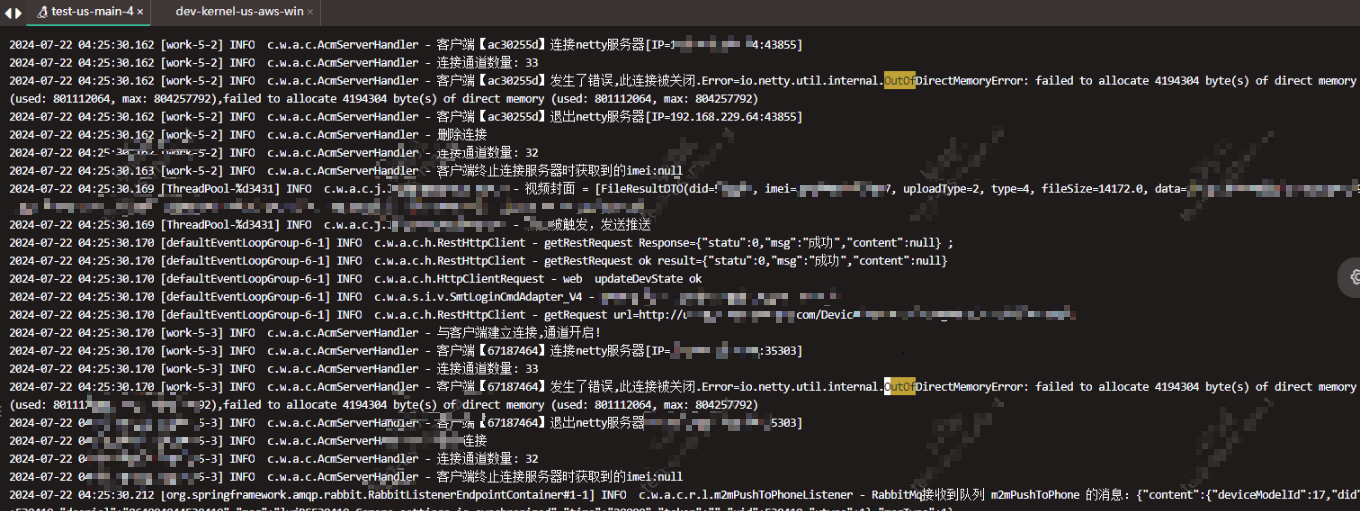
某次线上事故,生产环境某个服务突然发生实例重启,如下图,研发提供了日志、服务名称,除此之外未提供任何信息。

定位思路
照例三板斧,监控、日志、工具,由于是生产环境,出于安全考虑,未提供访问权限,也未提供资源监控和docker监控,只提供了日志和服务名称,因此我们无法通过监控、日志明显看出问题,接下来只能在测试环境构造数据进行压测,复现并优化该问题。
从日志看该业务是一个视频封面截取业务,因此单独针对该业务进行压测。
该业务需要设备先登录获取token,再根据token上传视频。
如下图,在测试环境压测复现
定位思路照例三板斧,监控、日志、工具,
首先排查监控,从资源监控、docker容器监控、jvm监控、业务监控顺序排查,
排查方向,CPU、内存资源,是否有明显峰刺,
docker容器,查看是否有重启等现象
jvm,排查gc、线程栈等情况
经过排查cpu、内存资源无明显异常,docker发生重启,排查jvm的gc情况和线程栈,如下图
线程数量明显不正常,线程一直增加
到这一步已经很明显了,线程无限增加导致直接内存溢出。
性能分析
上述步骤中,我们通过三板斧,已经确定了是线程无限增加问题,那么接下来深入分析是什么线程会无限增加,再根据线程找到代码,进行代码优化。
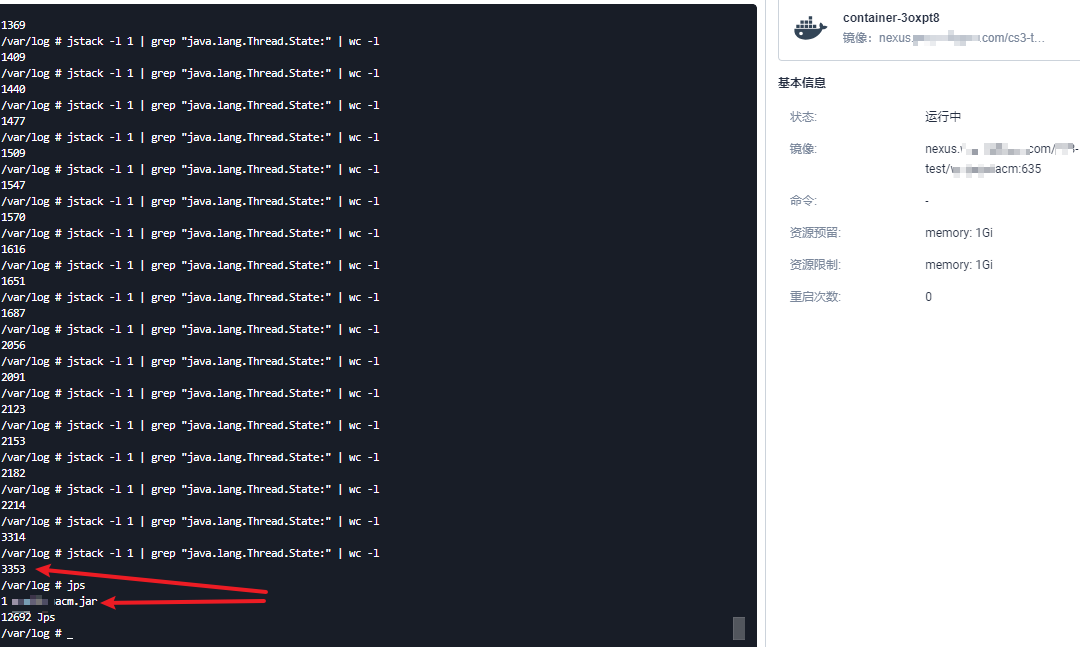
推荐使用ibm三剑客的开源工具,jca.jar,分析线程栈
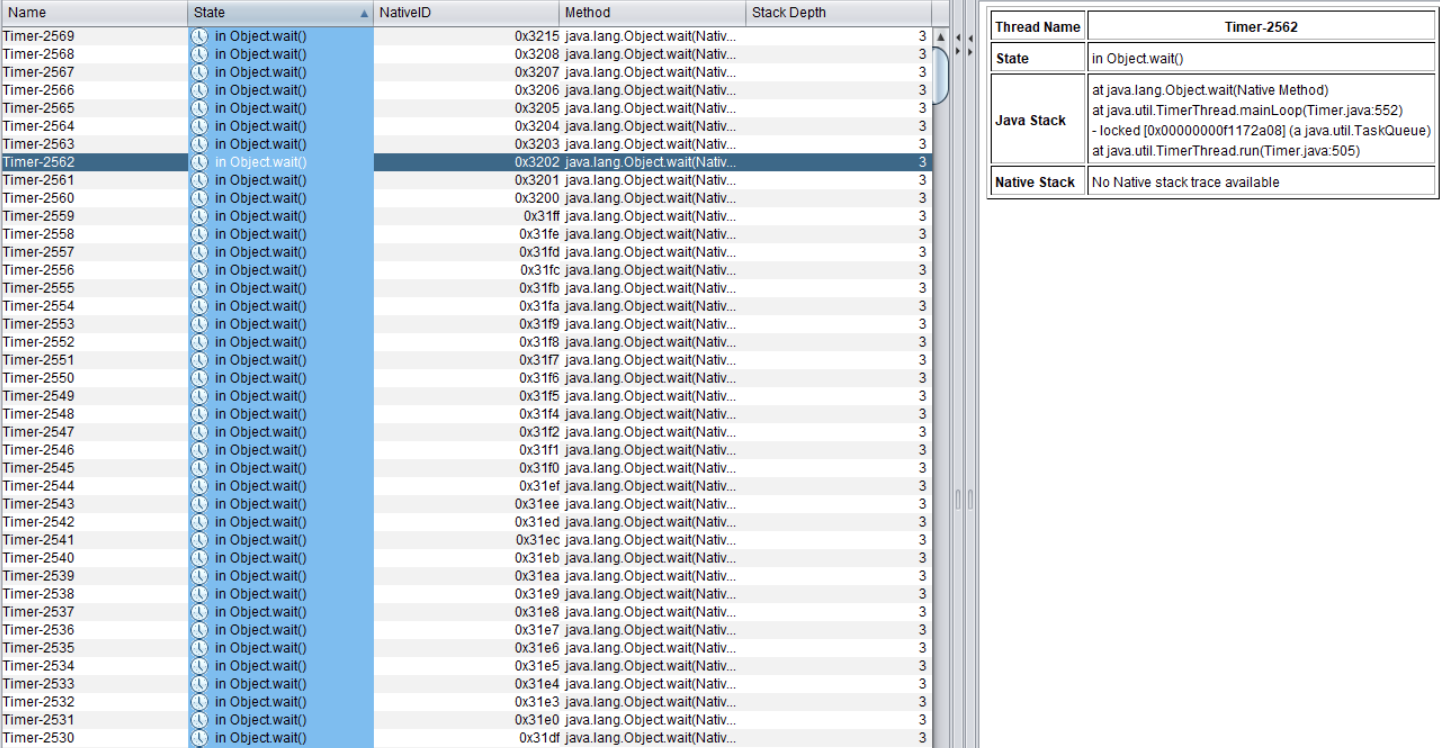
压测过程中,在docker容器中执行jstack -l 1 > jstack.log获取线程栈日志,通过jca.jar打开,如下图,

明显一眼看出是Object.wait()对象,
继续深入定位,存在大量的timer对象
代码定位
排查代码,如下图,
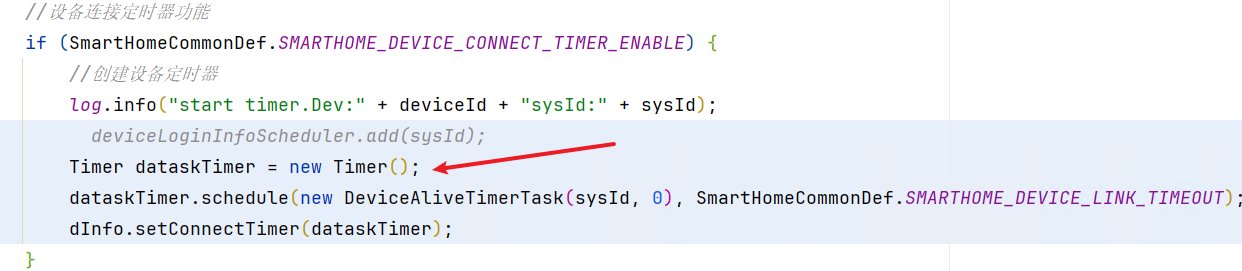

这段代码是为IoT设备创建一个连接超时定时器,超时时间是15min,结合上下文分析,此段代码是设备的免登录机制,
即设备登录时,后端会把设备的sysid(即登录token)存入双向映射键值对中(即BidiMap),如果设备登录15min之内未上传任何请求,则将其token删除

如下图,它允许通过 key 查找 value,也能通过 value 反向查找 key,且确保键和值都是唯一的(即 key 和 value 都不可重复)。
与hashMap不同,hashMap只能通过 key 查 value,但是BidiMap是双向查找

结合业务分析,已经很明显了,设备登录过程中,每次登录都会new一个timer对象,该对象存在15min,如果设备数量较少,短时间内不会有问题,但是近期业务量猛增,直到设备达到一定数量后,即使15min内登录无任何操作,量大了之后也必然会出现OOM。
这是一个经典的性能问题,在2019年上线之初,未考虑到未来几年的设备增量,导致设备数量上来后,必然出现OOM。
代码优化
结合业务,我们很容易想到用Redis、定时任务等方法可以轻松解决,但是领导层出于业务改动最小的考虑,不使用Redis,而是使用定时任务
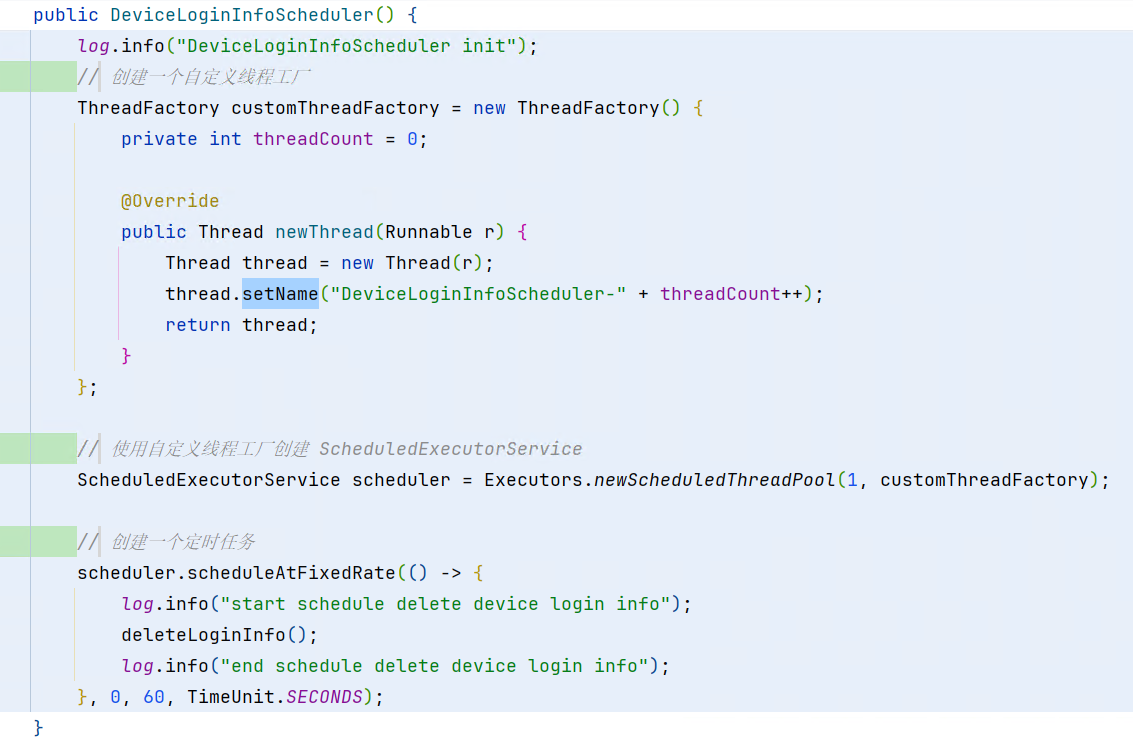
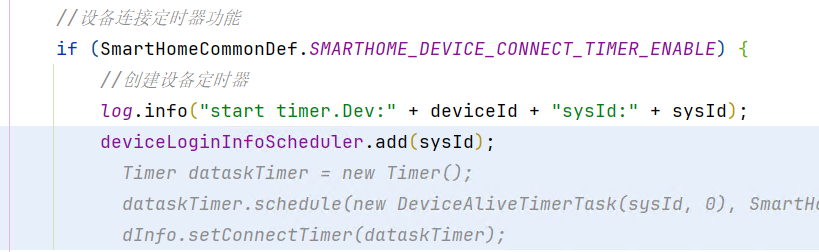
代码如下,弃用原有timer方案:
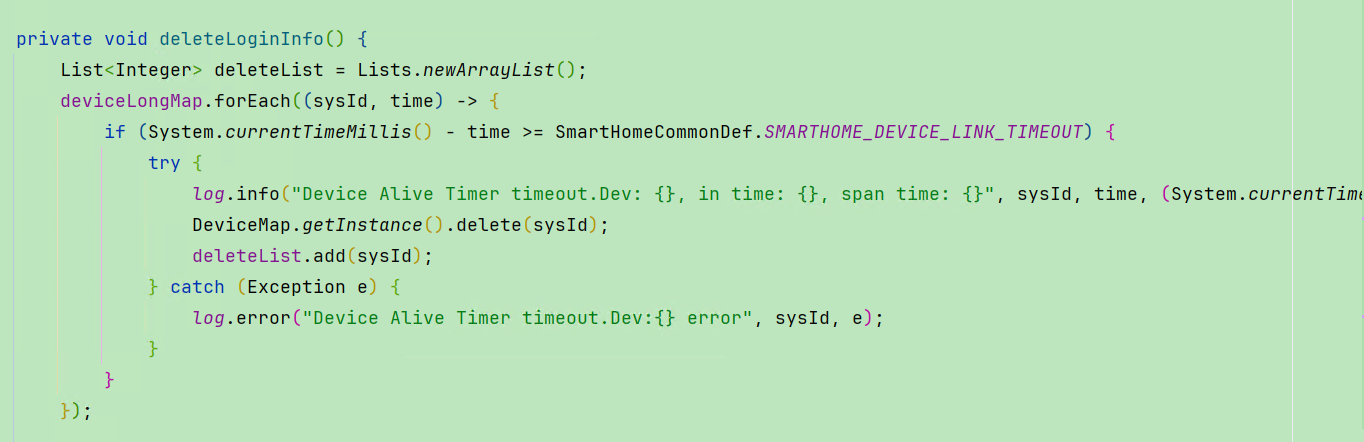
起一个单线程的定时任务线程池,该定时任务线程每60s执行一次,将从BidiMap中将设备的登录sysid给delete掉
成果检验
后续压测30min登录15万次都无明显异常,仅有一笔脏数据问题导致的失败。
经验总结
1、任何性能问题,基本都可以从监控、日志、工具3个方面排查,作者本人称之为性能分析三板斧。
2、任何性能问题的优化,都需要结合业务、成本、系统稳定性等综合考量,再确定优化方式。本文中,大家都知道使用redis效果会更好,但是出于成本、业务改动量、系统稳定性等方面考虑,还是弃用redis方案。
思维扩展
任何业务代码设计之处,就必须要考虑未来用户量增加的场景,并预留一定措施,本文就是一个非常经典的例子。