引言
本文用于记录作者在一个后台管理系统项目中遇到的页面查询慢SQL问题,以及优化过程。
问题现象
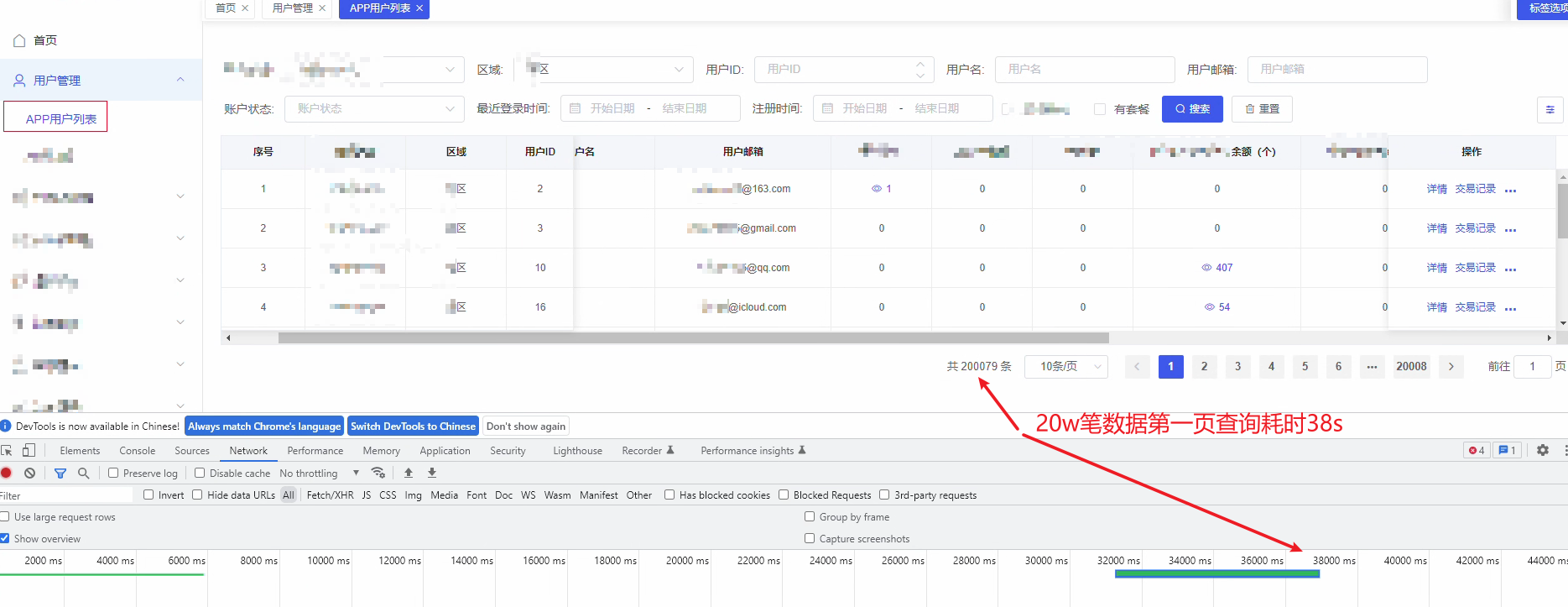
一个IoT设备后台管理系统的页面,查询用户列表比较慢,20万用户量级、10万设备量级,第一页10条数据查询耗时38s,
如下图,
性能分析
从业务上看,这只是一个后台查询页面,并无复杂的业务逻辑,因此作者凭经验判断大概率是SQL问题。
直接抓取SQL。抓取SQL有多种方式,如果你有MySQL数据库权限,
8.0以下直接通过客户端工具执行SHOW full PROCESSLIST ;,8.0以上版本执行SELECT * FROM performance_schema.processlist WHERE COMMAND IS NOT NULL;
如果没有数据库权限,看日志、获取使用其他工具如arthas等也可以抓到SQL。
如下图,这种明显比较慢的SQL一眼就能看出来
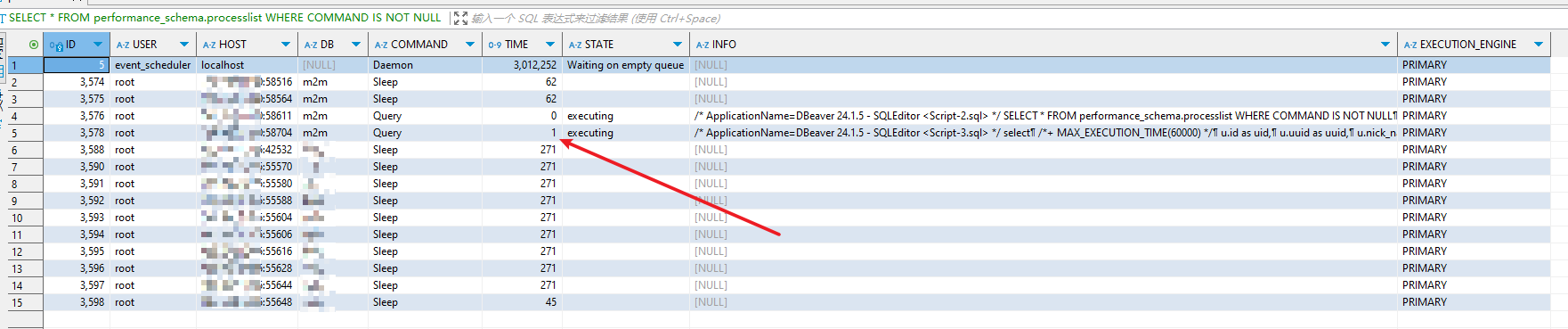
SELECT /*+ MAX_EXECUTION_TIME(60000) */
u.id AS uid,
u.uuid AS uuid,
u.nick_name AS nickName,
u.user_name userName,
u.user_email userEmail,
u.img_url avatar,
u.token AS phoneToken,
u.app_type AS appType,
u.appVersion,
u.area_id areaId,
u.`status`,
u.activation AS activation,
ui.hd_pic AS hd_pic_count,
ui.hd_video AS hd_video_count,
(ui.hd_pic + ui.hd_video) AS hd_count,
ui.live_stream AS live_stream,
u.country AS country_code,
u.user_language as lang_code,
(select count(d.id)
from m2m.device d
where d.uid = u.id and d.dstatus = 1
) as cam_count,
(select count(ci.id)
from m2m.camera_image ci
where ci.uid = u.id and ci.`status` = 1
) as photo_num,
u.login_type loginType,
1 as loginWay,
u.login_time loginTime,
u.create_time createTime,
u.logout,
u.is_del AS del_status,
ui.integral,
u.test_flag,
ui.balance
FROM
m2m_user.user u
LEFT JOIN m2m.user_info ui ON u.id = ui.uid
WHERE
u.app_type = 1
and u.area_id = 1 LIMIT 30,10;SQL优化
任何SQL优化都是从两方面入手,第一步理解SQL含义作用,判断是否需要这么实现,第二步如果业务实现没问题就查看执行计划为何会执行慢。
首先理解SQL的业务用途,从页面上看是查询所有的APP用户列表
从SQL本身来看,是user表与user_info表left join,查询时有两个子查询,分别是计算用户设备数量的子查询、计算用户的图像数量,初步看业务实现没问题,
理解了业务用途之后,再查看执行计划,如下图

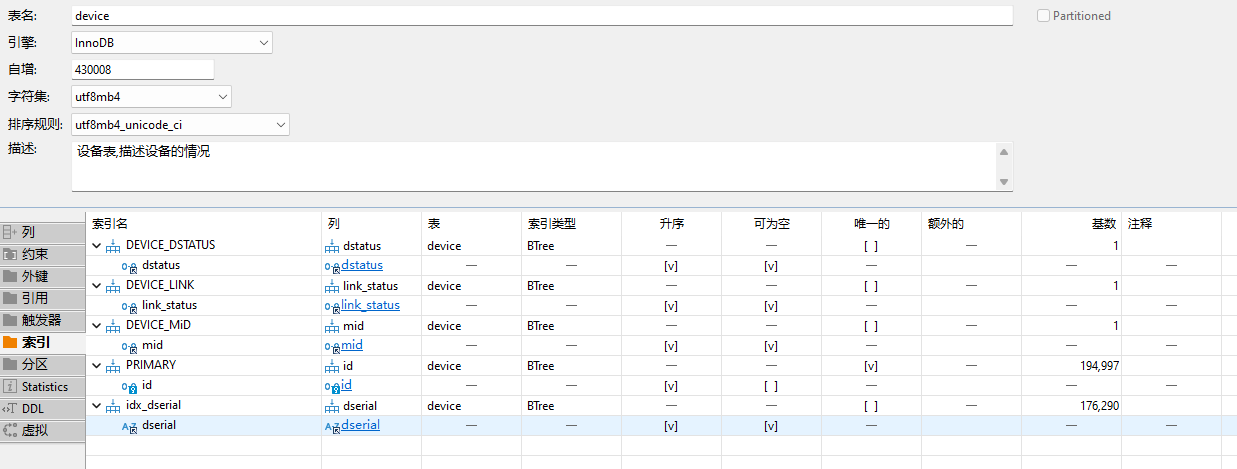
注意执行顺序是id=3211,ci表走了uid索引,无明显问题,但是d表走的是DEVICE_DSTATUS索引,这个索引对应的字段是DEVICE_DSTATUS,明显是经典的索引区分度不高,
如下图,device表索引
果然,查看该表的表结构,该字段值只有两个,不适合做索引,
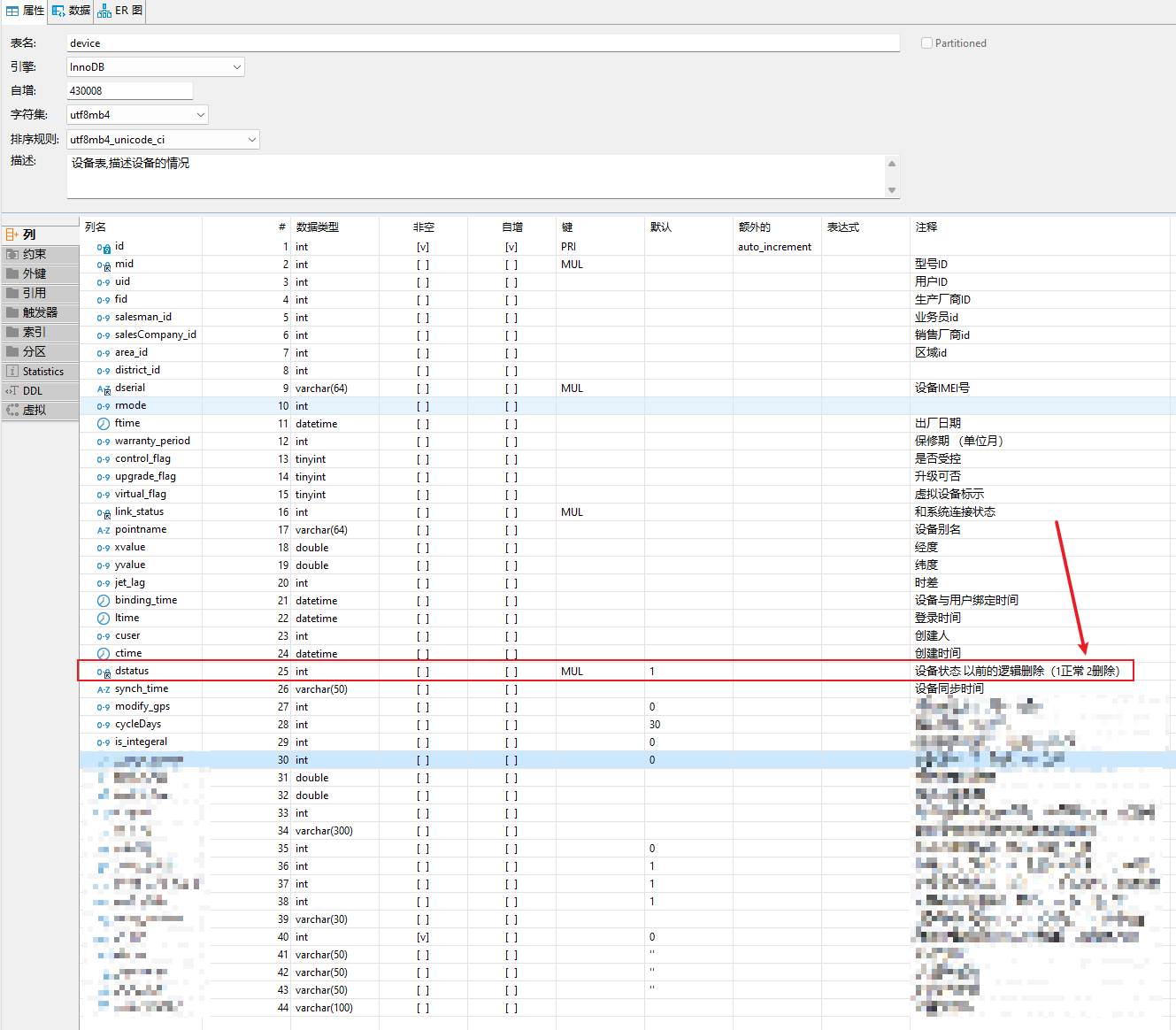
再来看子查询中的SQL语句,业务意义是查询设备绑定了用户且设备未被删除的数量
select count(d.id)
from m2m.device d
where d.uid = u.id and d.dstatus = 1优化原则是能走索引尽量走索引,而where语句中用到了d.uid = u.id,结合业务分析,单个用户最多绑定几台设备,这样20万用户的情况下,区分度明显远超dstatus,因此,考虑新增的d.uid索引,弃用d.dstatus索引
如下图

成果检验
优化效果,降低至22ms。

页面优化效果,从38s降低至1.3s,由于服务器部署在美国,我们中国跨大洲访问美国的服务器耗时很长,再加上前端渲染等因素,1.3s已经很快了,因此后续不再优化。

思维扩展
本文中的执行计划解读,如下图,子查询d表的rows表示MySQL估计需要扫描的行数(预估值,不准),这个值通常越小越好,越小表示需要扫描的行数越少、SQL越快,而filtered=100%,表示查询条件完全被索引覆盖(存储引擎返回的行100%满足条件,无需服务器层过滤,这是最理想的情况),这两个值通常结合起来看,例如本文中的ui与u表的匹配,

优化后的执行计划,虽然filtered=10%,但是通过rows=1优化效果已经达到预期了。
